This article is part of a series of articles about the Thread Pool Services interface used for multithreading. For the previous article, see Part 1.
Processing raster images using multiple threads
This is another typical task that is a good fit for optimization using multithreading. Raster images can consist of billions of pixels, each of them can be processed and sometimes calculation per pixel can be very complex. The best case is if processing each separate pixel doesn’t influence the others, which means that threads can run simultaneously without additional synchronization (mutexes, events, and so on). Tasks in which threads work only with their heap of data and don’t influence other processing threads is the best place for multithreaded optimizations.
Prerequisites
For an example of using multithreading for raster image processing, we will generate a single final image from all images, generated from the previous step (loading and rendering multiple databases). For this task we can write a raster image wrapper (for more information about raster image wrappers read “Image processing using Teigha raster image wrappers (November 2016 )” article) , which will compute the average color for each pixel in the requested scanline during a scanLines method call:
// Raster image generator (combine input images into single image)
class GeneratedRasterImage : public OdGiRasterImageWrapper
{
protected:
OdGiRasterImagePtrArray m_inputImages;
public:
virtual const OdUInt8* scanLines() const { return NULL; }
virtual void scanLines(OdUInt8* scnLines, OdUInt32 firstScanline, OdUInt32 numLines = 1) const
{
OdUInt32 scanLen = scanLineSize(), pixWidth = pixelWidth() * 3;
OdArray<OdUInt8Array> inputScanlines;
inputScanlines.resize(m_inputImages.size());
for (OdUInt32 i = firstScanline; i < firstScanline + numLines; i++)
{
for (OdUInt32 nImage = 0; nImage < inputScanlines.size(); nImage++)
{
inputScanlines[nImage].resize(scanLen);
m_inputImages[nImage]->scanLines(inputScanlines[nImage].asArrayPtr(), i);
}
OdUInt8 *pScanLine = scnLines + ((i - firstScanline) * scanLen);
for (OdUInt32 nPixel = 0; nPixel < pixWidth; nPixel += 3)
{
double clrMerge[3] = { 0.0, 0.0, 0.0 };
for (OdUInt32 nImage = 0; nImage < inputScanlines.size(); nImage++)
{
clrMerge[0] += inputScanlines[nImage][nPixel + 0];
clrMerge[1] += inputScanlines[nImage][nPixel + 1];
clrMerge[2] += inputScanlines[nImage][nPixel + 2];
}
clrMerge[0] /= inputScanlines.size();
clrMerge[1] /= inputScanlines.size();
clrMerge[2] /= inputScanlines.size();
pScanLine[nPixel + 0] = (OdUInt8)clrMerge[0];
pScanLine[nPixel + 1] = (OdUInt8)clrMerge[1];
pScanLine[nPixel + 2] = (OdUInt8)clrMerge[2];
}
}
}
GeneratedRasterImage() {}
void configureImage(const OdGiRasterImage *pOriginal, OdGiRasterImagePtrArray &inputImages)
{
setOriginal(pOriginal);
m_inputImages = inputImages;
}
};
Since the GeneratedRasterImage class computes requested pixels in a scanline on demand, we need an additional raster image wrapper, which will simply hold the result of image processing and return it without any additional calculations during further image saving:
// Container for processed raster image
class ProcessedRasterImage : public OdGiRasterImageWrapper
{
OdUInt8Array m_processedPixels;
public:
virtual const OdUInt8* scanLines() const { return m_processedPixels.getPtr(); }
virtual void scanLines(OdUInt8* scnLines, OdUInt32 firstScanline, OdUInt32 numLines = 1) const
{
const OdUInt8 *pixData = m_processedPixels.getPtr();
const OdUInt32 scnSize = scanLineSize();
::memcpy(scnLines, pixData + scnSize * firstScanline, numLines * scnSize);
}
void process(OdUInt32 firstScanline, OdUInt32 numLines = 1)
{
original()->scanLines(m_processedPixels.asArrayPtr() + scanLineSize() * firstScanline, firstScanline, numLines);
}
ProcessedRasterImage() {}
void configureImage(const OdGiRasterImage *pOriginal)
{
setOriginal(pOriginal);
m_processedPixels.resize(scanLineSize() * pixelHeight());
}
};
Of course, in a more high-grade application, GeneratedRasterImage and ProcessedRasterImage classes can be merged into a single class that can keep precomputed results internally and doesn’t recompute them with each scanLines method call. But this change will complicate the following example, so we skipped both classes to be more illustrative.
The ProcessedRasterImage::process call invokes the GeneratedRasterImage::scanLines method to compute pixels in the requested scanlines and stores the result inside an internal array. Each thread will compute its own set of scanlines.
Now we can construct and set up both GeneratedRasterImage and ProcessedRasterImage classes:
// Create final raster image generator
OdSmartPtr<GeneratedRasterImage> pGenImage = OdRxObjectImpl<GeneratedRasterImage>::createObject();
pGenImage->configureImage(generatedRasters[0], generatedRasters);
// Create container for processed final raster image
OdSmartPtr<ProcessedRasterImage> pProcImage = OdRxObjectImpl<ProcessedRasterImage>::createObject();
pProcImage->configureImage(pGenImage);
Running processing in multiple threads
As in the previous article, first we construct a queue for multithread tasks:
pMTQueue = pThreadPool->newMTQueue(ThreadsCounter::kNoAttributes, 4, kMtQueueAllowExecByMain);
The newMTQueue method arguments are now different:
- We have a simple task that doesn’t invoke complex processes, such as database loading or vectorization, so we pass ThreadsCounter::kNoAttributes in the first argument instead of setting flags. ThreadsCounter::kNoAttributes means that no additional thread initialization or uninitialization is required.
- We pass 4 as the second argument. This means that we know exactly that our task requires four threads, and this knowledge optimizes thread allocation. Moreover this guarantees that exactly four threads will be used for our task execution; if the thread pool doesn’t have enough free threads, it will spawn them.
- We pass an additional kMtQueueAllowExecByMain flag in the third argument. This flag instructs the multithreading queue to use the main process thread as one of the auxiliary threads. It is not recommended to use this flag for execution of complex tasks (which invoke database loading or vectorization processes), since they may require execution of some subtasks onto the level of the main process thread. But for simple tasks, like raster image processing, usage of this flag is justified since the multithreading queue can allocate only three auxiliary threads and invoke the main process thread that is already available for the last subtask, otherwise the main process thread will simply wait until the end of the execution of all threads.
Now we can run our four threads for raster image processing:
// Run threads for raster image processing
const OdUInt32 nScanlinesPerThread = pProcImage->pixelHeight() / 4;
for (OdUInt32 nThread = 0; nThread < 4; nThread++)
{
OdUInt32 nScanlinesPerThisThread = nScanlinesPerThread;
if (nThread == 3) // Height can be not dividable by 2, so last thread can have onto one scanline less.
nScanlinesPerThisThread = pProcImage->pixelHeight() - nScanlinesPerThread * 3;
pMTQueue->addEntryPoint(OdRxObjectImpl<ProcessImageCaller>::createObject()->setup(pProcImage, nScanlinesPerThread * nThread, nScanlinesPerThisThread), (OdApcParamType)NULL);
}
This part of the code is very similar to the previous article’s code for database loading and rendering. The difference is that we don’t require passing of data to threads using the last addEntryPoint method argument; so simply pass NULL. Each thread will process their part of scanlines; the last thread (depending on image height) can process one scanline fewer than the others.
Wait until thread completion and release the multithreading queue, since it will not be required any more:
// Wait threads completion
pMTQueue->wait();
pMTQueue.release();
And finally, save the generated output raster image (for more information about raster image saving, see “Image processing using Teigha raster image wrappers (November 2016 )” article):
// Save output image
OdRxRasterServicesPtr pRasSvcs = odrxDynamicLinker()->loadApp(RX_RASTER_SERVICES_APPNAME, false);
if (pRasSvcs.isNull()) // Check that raster services module correctly loaded
throw OdError(eNullPtr);
bool bSaveState = pRasSvcs->saveRasterImage(pProcImage, outputFileName);
if (!bSaveState)
throw OdError(eFileWriteError);
For testing, we have four input drawings:

Drawing with 1024 lines |

Drawing with 1024 circles |
|
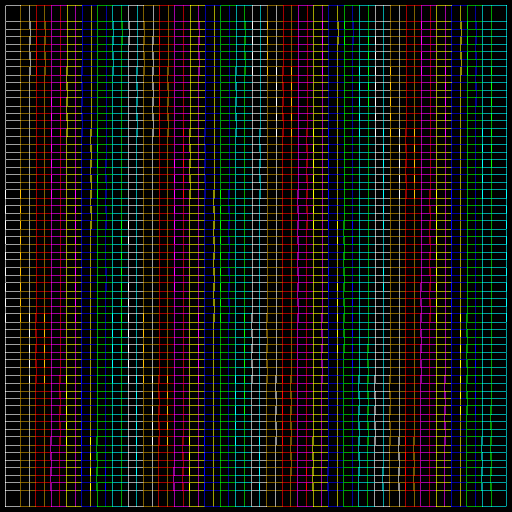
Drawing with 1024 rectangular polylines |
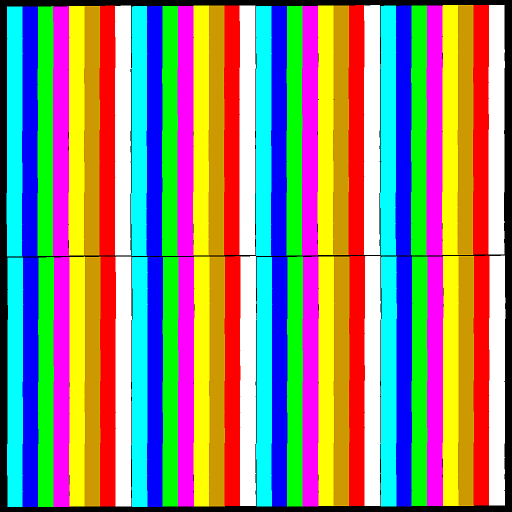
Drawing with 1024 rectangular solids |
The final generated raster image (result of merging four input images) looks like this:

Result of merging four input raster images into a final raster image
The next article will describe measuring the performance of using multiple threads.

