本文是关于用于多线程的线程池服务接口系列文章的一部分。有关上一篇文章,请参阅第 1 部分。
使用多线程处理栅格图像
这是另一个非常适合使用多线程进行优化的典型任务。栅格图像可以由数十亿像素组成,每个像素都可以进行处理,有时每个像素的计算可能非常复杂。最好的情况是,如果处理每个单独的像素不会影响其他像素,这意味着线程可以同时运行而无需额外的同步(互斥锁、事件等)。线程只处理自己的数据堆而不影响其他处理线程的任务是多线程优化的最佳场所。
先决条件
为了演示使用多线程进行栅格图像处理的示例,我们将从上一步(加载和渲染多个数据库)生成的所有图像中生成一个最终图像。对于此任务,我们可以编写一个栅格图像包装器(有关栅格图像包装器的更多信息,请阅读“使用 Teigha 栅格图像包装器进行图像处理(2016 年 11 月)”文章),它将在 scanLines 方法调用期间计算请求扫描行中每个像素的平均颜色:
// Raster image generator (combine input images into single image)
class GeneratedRasterImage : public OdGiRasterImageWrapper
{
protected:
OdGiRasterImagePtrArray m_inputImages;
public:
virtual const OdUInt8* scanLines() const { return NULL; }
virtual void scanLines(OdUInt8* scnLines, OdUInt32 firstScanline, OdUInt32 numLines = 1) const
{
OdUInt32 scanLen = scanLineSize(), pixWidth = pixelWidth() * 3;
OdArray<OdUInt8Array> inputScanlines;
inputScanlines.resize(m_inputImages.size());
for (OdUInt32 i = firstScanline; i < firstScanline + numLines; i++)
{
for (OdUInt32 nImage = 0; nImage < inputScanlines.size(); nImage++)
{
inputScanlines[nImage].resize(scanLen);
m_inputImages[nImage]->scanLines(inputScanlines[nImage].asArrayPtr(), i);
}
OdUInt8 *pScanLine = scnLines + ((i - firstScanline) * scanLen);
for (OdUInt32 nPixel = 0; nPixel < pixWidth; nPixel += 3)
{
double clrMerge[3] = { 0.0, 0.0, 0.0 };
for (OdUInt32 nImage = 0; nImage < inputScanlines.size(); nImage++)
{
clrMerge[0] += inputScanlines[nImage][nPixel + 0];
clrMerge[1] += inputScanlines[nImage][nPixel + 1];
clrMerge[2] += inputScanlines[nImage][nPixel + 2];
}
clrMerge[0] /= inputScanlines.size();
clrMerge[1] /= inputScanlines.size();
clrMerge[2] /= inputScanlines.size();
pScanLine[nPixel + 0] = (OdUInt8)clrMerge[0];
pScanLine[nPixel + 1] = (OdUInt8)clrMerge[1];
pScanLine[nPixel + 2] = (OdUInt8)clrMerge[2];
}
}
}
GeneratedRasterImage() {}
void configureImage(const OdGiRasterImage *pOriginal, OdGiRasterImagePtrArray &inputImages)
{
setOriginal(pOriginal);
m_inputImages = inputImages;
}
};
由于 GeneratedRasterImage 类按需计算扫描行中请求的像素,因此我们需要一个额外的栅格图像包装器,它将简单地保存图像处理结果并在后续图像保存期间不进行任何额外计算地返回它:
// Container for processed raster image
class ProcessedRasterImage : public OdGiRasterImageWrapper
{
OdUInt8Array m_processedPixels;
public:
virtual const OdUInt8* scanLines() const { return m_processedPixels.getPtr(); }
virtual void scanLines(OdUInt8* scnLines, OdUInt32 firstScanline, OdUInt32 numLines = 1) const
{
const OdUInt8 *pixData = m_processedPixels.getPtr();
const OdUInt32 scnSize = scanLineSize();
::memcpy(scnLines, pixData + scnSize * firstScanline, numLines * scnSize);
}
void process(OdUInt32 firstScanline, OdUInt32 numLines = 1)
{
original()->scanLines(m_processedPixels.asArrayPtr() + scanLineSize() * firstScanline, firstScanline, numLines);
}
ProcessedRasterImage() {}
void configureImage(const OdGiRasterImage *pOriginal)
{
setOriginal(pOriginal);
m_processedPixels.resize(scanLineSize() * pixelHeight());
}
};
当然,在更高级别的应用程序中,GeneratedRasterImage 和 ProcessedRasterImage 类可以合并为一个类,该类可以在内部保存预计算的结果,并且不会在每次 scanLines 方法调用时重新计算它们。但是这种更改会使以下示例复杂化,因此我们跳过了这两个类,以使其更具说明性。
ProcessedRasterImage::process 调用 GeneratedRasterImage::scanLines 方法来计算请求扫描行中的像素,并将结果存储在内部数组中。每个线程将计算自己的一组扫描行。
现在我们可以构造并设置 GeneratedRasterImage 和 ProcessedRasterImage 类:
// Create final raster image generator
OdSmartPtr<GeneratedRasterImage> pGenImage = OdRxObjectImpl<GeneratedRasterImage>::createObject();
pGenImage->configureImage(generatedRasters[0], generatedRasters);
// Create container for processed final raster image
OdSmartPtr<ProcessedRasterImage> pProcImage = OdRxObjectImpl<ProcessedRasterImage>::createObject();
pProcImage->configureImage(pGenImage);
在多个线程中运行处理
与上一篇文章一样,我们首先为多线程任务构建一个队列:
pMTQueue = pThreadPool->newMTQueue(ThreadsCounter::kNoAttributes, 4, kMtQueueAllowExecByMain);
newMTQueue 方法的参数现在不同了:
- 我们有一个不涉及复杂过程(例如数据库加载或矢量化)的简单任务,因此我们在第一个参数中传递 ThreadsCounter::kNoAttributes 而不是设置标志。ThreadsCounter::kNoAttributes 意味着不需要额外的线程初始化或反初始化。
- 我们将 4 作为第二个参数传递。这意味着我们确切地知道我们的任务需要四个线程,并且此知识可以优化线程分配。此外,这保证了我们的任务执行将精确使用四个线程;如果线程池没有足够的空闲线程,它将生成它们。
- 我们在第三个参数中传递了一个额外的 kMtQueueAllowExecByMain 标志。此标志指示多线程队列使用主进程线程作为辅助线程之一。不建议将此标志用于执行复杂任务(涉及数据库加载或矢量化过程),因为它们可能需要将某些子任务执行到主进程线程级别。但对于简单的任务,例如栅格图像处理,使用此标志是合理的,因为多线程队列只能分配三个辅助线程,并调用已可用于最后一个子任务的主进程线程,否则主进程线程将简单地等待所有线程执行结束。
现在我们可以运行四个线程进行栅格图像处理:
// Run threads for raster image processing
const OdUInt32 nScanlinesPerThread = pProcImage->pixelHeight() / 4;
for (OdUInt32 nThread = 0; nThread < 4; nThread++)
{
OdUInt32 nScanlinesPerThisThread = nScanlinesPerThread;
if (nThread == 3) // Height can be not dividable by 2, so last thread can have onto one scanline less.
nScanlinesPerThisThread = pProcImage->pixelHeight() - nScanlinesPerThread * 3;
pMTQueue->addEntryPoint(OdRxObjectImpl<ProcessImageCaller>::createObject()->setup(pProcImage, nScanlinesPerThread * nThread, nScanlinesPerThisThread), (OdApcParamType)NULL);
}
这部分代码与上一篇文章中用于数据库加载和渲染的代码非常相似。不同之处在于,我们不需要使用最后一个 addEntryPoint 方法参数将数据传递给线程;因此只需传递 NULL。每个线程将处理其部分的扫描线;最后一个线程(取决于图像高度)可以比其他线程少处理一条扫描线。
等待线程完成并释放多线程队列,因为它将不再需要:
// Wait threads completion
pMTQueue->wait();
pMTQueue.release();
最后,保存生成的输出栅格图像(有关栅格图像保存的更多信息,请参阅“使用 Teigha 栅格图像包装器进行图像处理(2016 年 11 月)”文章):
// Save output image
OdRxRasterServicesPtr pRasSvcs = odrxDynamicLinker()->loadApp(RX_RASTER_SERVICES_APPNAME, false);
if (pRasSvcs.isNull()) // Check that raster services module correctly loaded
throw OdError(eNullPtr);
bool bSaveState = pRasSvcs->saveRasterImage(pProcImage, outputFileName);
if (!bSaveState)
throw OdError(eFileWriteError);
为了测试,我们有四张输入图纸:

包含 1024 条线的图纸 |
|

包含 1024 个圆的图纸 |
|
|
|
|
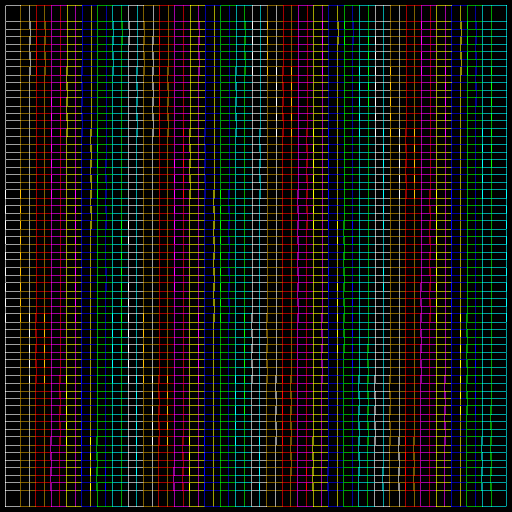
包含 1024 条矩形多段线的图纸 |
|
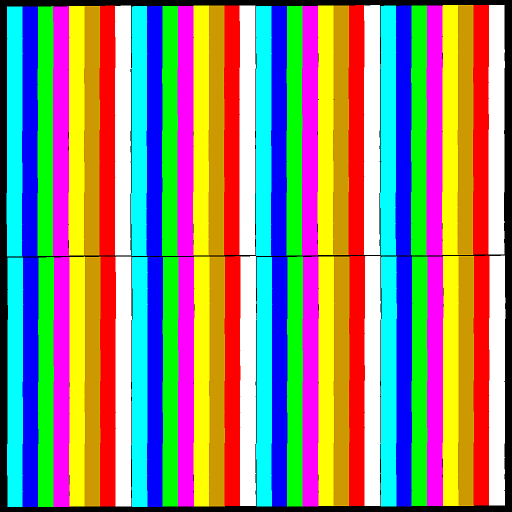
包含 1024 个矩形实体的图纸 |
最终生成的栅格图像(合并四个输入图像的结果)如下所示:

将四个输入栅格图像合并为最终栅格图像的结果
下一篇文章将介绍如何衡量使用多线程的性能。

